Cómo construí un servidor MCP con Python, Clean Architecture y logging en MongoDB
Del protocolo al código: un recorrido técnico completo con FastMCP, SQLite y middleware asíncrono.
Agarrá un café o un mate — esto va para largo.
En este proyecto metí más de 15 cosas al mismo tiempo: Model Context Protocol, Clean Architecture, Python, SQLite, FastMCP, inyección de dependencias, repositorios abstractos, Pydantic, middleware asíncrono, MongoDB, Motor, Docker Compose, Mongo Express, pytest con fixtures, tests de integración con skip automático, rate limiting con ventana deslizante, logging contextual y conexión con un IDE con agentes de IA.
Si querés tener una masterclass de todos esos conceptos, bienvenido/a. Solo necesitás paciencia — y si en algún momento te perdés, tenés mi correo.
El por qué de tanto a la vez es simple: la mayoría de los ejemplos de MCP que encontré eran scripts de 50 líneas sin estructura. Funcionaban, sí. Pero no eran algo que pudieras mantener, escalar ni llevar a producción. Me propuse construir algo diferente: un servidor MCP con arquitectura limpia, middlewares reales y logging persistente.
Este artículo documenta todo ese proceso — incluyendo los errores que cometí y cómo los resolví.
El repo está acá: github.com/gmaron/mcp-sqlite-server
¿Qué es MCP y por qué debería importarte?
El Model Context Protocol es un estándar abierto que define cómo los modelos de IA se conectan con fuentes de datos y herramientas externas. En lugar de escribir prompts con contexto hardcodeado, un servidor MCP le da al modelo acceso a herramientas (tools) y recursos (resources) que puede invocar cuando lo necesita.
La tabla conceptual es simple:
- Tool: Función que el modelo puede llamar (ej:
obtener_usuarios,process_transaction) - Resource Datos de solo lectura accesibles por URI (ej:
db://usuarios/todos) - Middleware Capa intermedia para logging, rate-limiting, manejo de errores
Si trabajás con LLMs integrados en IDEs como Antigravity (o Cursor, Windsurf), MCP es el protocolo que conecta tu agente con el mundo real. Vale la pena entenderlo bien.
Lo que construí
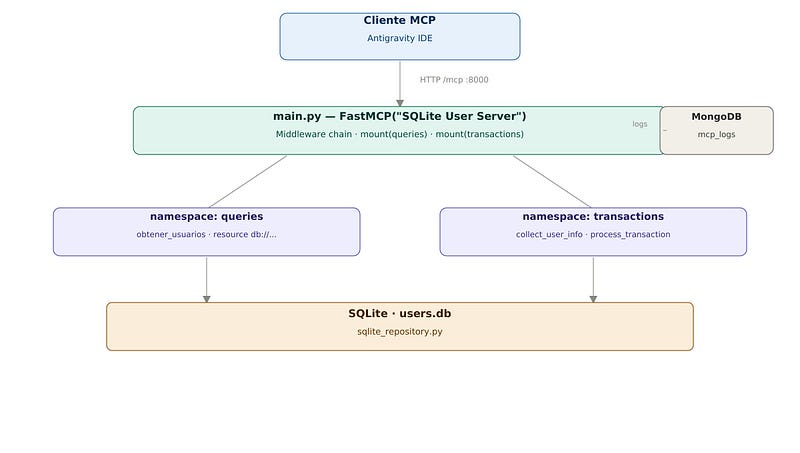
Un servidor MCP en Python que expone una base de datos SQLite a través de tools y resources, con:
- Clean Architecture (Domain → Application → Infrastructure)
- FastMCP 3.x como framework del servidor
- Middleware chain con logging a MongoDB, rate-limiting y error handling
- Tests unitarios y de integración con pytest
- Docker Compose para MongoDB + Mongo Express
- Integración con Antigravity IDE
La arquitectura
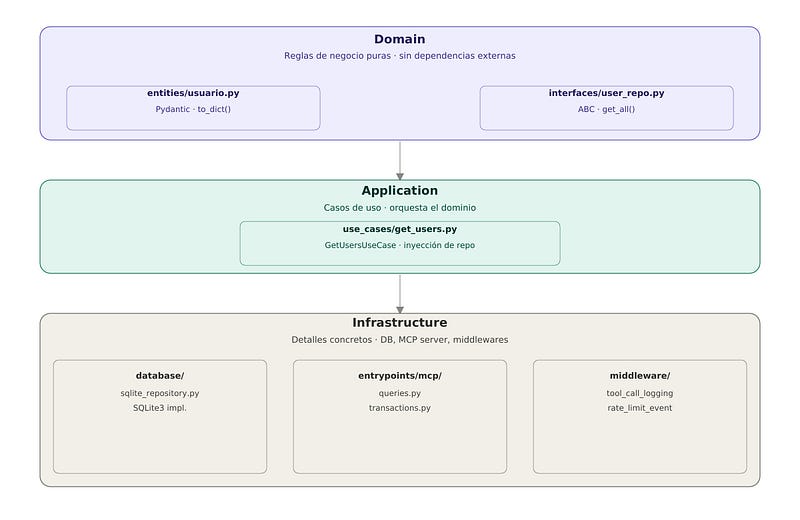
Elegí Clean Architecture porque MCP no es distinto a cualquier otro entrypoint de una aplicación. Un servidor MCP es solo una forma más de exponer lógica de negocio, igual que una API REST o un CLI.
La estructura quedó así:
mcp-sqlite-server/
├── app/
│ ├── domain/
│ │ ├── entities/usuario.py # Entidad con Pydantic
│ │ └── interfaces/user_repository.py # Interfaz abstracta
│ ├── application/
│ │ └── use_cases/get_users.py # Caso de uso
│ └── infrastructure/
│ ├── database/sqlite_repository.py # Implementación concreta
│ ├── entrypoints/mcp/resources/
│ │ ├── queries.py # Sub-servidor de queries
│ │ └── transactions.py # Sub-servidor de transactions
│ └── middleware/
│ ├── mongo_config.py
│ ├── tool_call_logging_middleware.py
│ └── rate_limit_event_middleware.py
├── tests/
│ ├── unit/
│ └── integration/
├── main.py
├── setup_db.py
└── docker-compose.ymlLa clave es que main.py no sabe nada de SQLite ni de MongoDB — solo monta sub-servidores y encadena middlewares. Cada capa tiene una sola responsabilidad.
El dominio: Pydantic como base
La entidad Usuario usa Pydantic v2 para validación y serialización:
# app/domain/entities/usuario.py
from pydantic import BaseModel
from typing import Optionalclass Usuario(BaseModel):
id: int
nombre: str
apellido: str
edad: int
profesion: str
nacionalidad: str
email: Optional[str] = Nonedef to_dict(self) -> dict:
return self.model_dump()
Y la interfaz del repositorio define el contrato sin acoplarse a ninguna implementación:
# app/domain/interfaces/user_repository.py
from abc import ABC, abstractmethod
from typing import Optional
from app.domain.entities.usuario import Usuarioclass UserRepository(ABC):
@abstractmethod
def get_all(self, nacionalidad: Optional[str] = None) -> list[Usuario]:
...
Esta separación hace que los tests unitarios no necesiten ninguna base de datos real — podés mockear el repositorio y testear el caso de uso en aislamiento total.
El caso de uso
El caso de uso es el corazón de la aplicación. Recibe el repositorio por inyección de dependencias:
# app/application/use_cases/get_users.py
from typing import Optional
from app.domain.entities.usuario import Usuario
from app.domain.interfaces.user_repository import UserRepositoryclass GetUsersUseCase:
def __init__(self, repository: UserRepository):
self.repository = repositorydef execute(self, nacionalidad: Optional[str] = None) -> list[Usuario]:
return self.repository.get_all(nacionalidad)
Simple, testeable, sin dependencias de infraestructura.
FastMCP: la decisión clave del framework
Acá tuve mi primer error importante. Empecé con el SDK oficial de MCP:
from mcp.server.fastmcp import FastMCP # ❌ SDK v1.0El problema: el SDK oficial v1.0 no soporta mount. Si querés sub-servidores con namespaces separados, necesitás el paquete standalone fastmcp (v3.x):
from fastmcp import FastMCP # ✅ FastMCP 3.xpip install fastmcpLa diferencia es sutil en el import pero fundamental en capacidades. FastMCP 3.x tiene mount, middleware chain, transporte HTTP streamable, y una API mucho más ergonómica.
Sub-servidores con namespace
FastMCP permite montar sub-servidores independientes, cada uno con sus propios tools y resources:
# app/infrastructure/entrypoints/mcp/resources/queries.py
from fastmcp import FastMCP
from app.application.use_cases.get_users import GetUsersUseCase
from app.infrastructure.database.sqlite_repository import SqliteUserRepository
from typing import Optionalqueries = FastMCP("queries")repo = SqliteUserRepository()
get_users_use_case = GetUsersUseCase(repo)@queries.tool()
def obtener_usuarios(nacionalidad: Optional[str] = None) -> list[dict]:
"""
Obtiene la lista de usuarios registrados en la base de datos.
Opcionalmente filtra por nacionalidad (ej: 'Argentina', 'Brasil').
Retorna una lista de objetos con los campos: id, nombre, apellido,
edad, profesion, nacionalidad, email.
"""
usuarios = get_users_use_case.execute(nacionalidad)
return [u.to_dict() for u in usuarios]@queries.resource("db://usuarios/todos")
def resource_usuarios() -> str:
"""Retorna todos los usuarios como texto formateado."""
usuarios = get_users_use_case.execute()
return "\n".join([
f"{u.id}: {u.nombre} {u.apellido} ({u.profesion}, {u.nacionalidad})"
for u in usuarios
])
Dos puntos importantes acá:
- El docstring del tool es crítico. El modelo lo lee para decidir cuándo y cómo invocar la herramienta. Un docstring vago produce invocaciones imprecisas.
- Siempre retornar
list[dict], no entidades de dominio. MCP serializa a JSON para el LLM, y Pydantic models no siempre se serializan correctamente sinto_dict().
El segundo error: la sintaxis de mount
Cuando finalmente tuve el paquete correcto, me encontré con este error:
'str' object has no attribute '_lifespan'La causa: estaba usando la sintaxis incorrecta de mount:
mcp.mount("queries", queries) # ❌ sintaxis viejaEn FastMCP 3.x, el servidor va primero y el namespace es keyword argument:
mcp.mount(queries, namespace="queries") # ✅Diferencia de un argumento. Media hora de debugging. Lo dejo documentado porque es exactamente el tipo de error que no aparece claro en ningún lado.
El tercer error: el transporte
SSE (Server-Sent Events) está deprecado en FastMCP 3.x. Si lo usás, vas a ver este error en el cliente:
unsupported content type "text/html"La solución es usar HTTP streamable:
# Al correr con fastmcp CLI:
fastmcp run main.py:mcp --transport http --port 8000El servidor queda en http://127.0.0.1:8000/mcp.
La cadena de middlewares
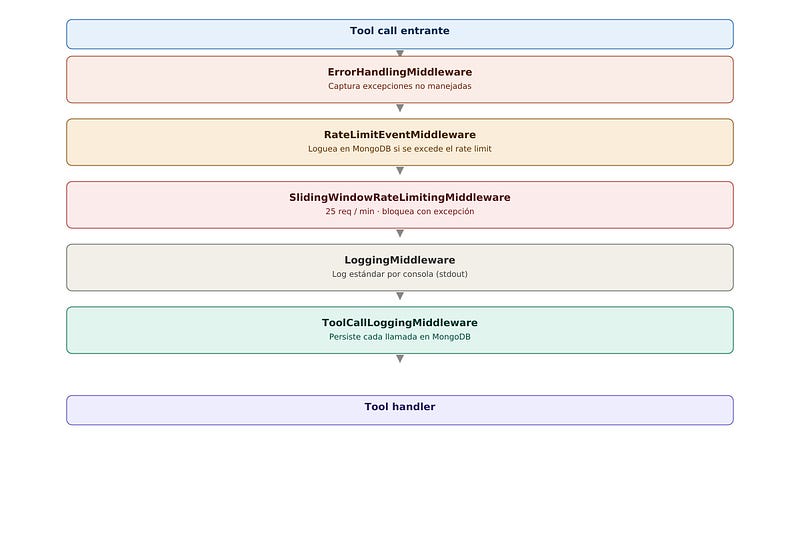
Esta fue la parte más interesante del proyecto. FastMCP permite encadenar middlewares que interceptan cada llamada a un tool:
# main.py
from fastmcp import FastMCP
from fastmcp.server.middleware.error_handling import ErrorHandlingMiddleware
from fastmcp.server.middleware.rate_limiting import SlidingWindowRateLimitingMiddleware
from fastmcp.server.middleware.logging import LoggingMiddleware
from app.infrastructure.entrypoints.mcp.resources.queries import queries
from app.infrastructure.entrypoints.mcp.resources.transactions import transactions
from app.infrastructure.middleware.tool_call_logging_middleware import ToolCallLoggingMiddleware
from app.infrastructure.middleware.rate_limit_event_middleware import RateLimitEventMiddlewaremcp = FastMCP("SQLite User Server")mcp.mount(queries, namespace="queries")
mcp.mount(transactions, namespace="transactions")mcp.add_middleware(ErrorHandlingMiddleware())
mcp.add_middleware(RateLimitEventMiddleware()) # antes del rate limiter
mcp.add_middleware(SlidingWindowRateLimitingMiddleware(max_requests=25, window_minutes=1))
mcp.add_middleware(LoggingMiddleware())
mcp.add_middleware(ToolCallLoggingMiddleware())if __name__ == "__main__":
mcp.run(transport="http", host="127.0.0.1", port=8000)
El orden importa: RateLimitEventMiddleware va antes que el rate limiter para poder capturar la excepción que este lanza y loguearla en MongoDB.
Logging a MongoDB con motor
El middleware de logging persiste cada llamada a tool en MongoDB usando motor, el driver async:
# app/infrastructure/middleware/tool_call_logging_middleware.py
from datetime import datetime, timezone
from fastmcp.server.middleware import Middleware, MiddlewareContext
from motor.motor_asyncio import AsyncIOMotorClient
import osclient = AsyncIOMotorClient(os.getenv("MONGO_URI", "mongodb://localhost:27017/"))
collection = client[os.getenv("MONGO_DATABASE", "mcp_logs")]["tool_calls"]class ToolCallLoggingMiddleware(Middleware):
async def on_call_tool(self, context: MiddlewareContext, call_next):
start = datetime.now(timezone.utc)
error = None
result = None
try:
result = await call_next(context)
except Exception as e:
error = str(e)
raise
finally:
msg = context.message
await collection.insert_one({
"tool_name": msg.params.name,
"arguments": dict(msg.params.arguments or {}),
"session_id": context.fastmcp_context.session_id,
"request_id": context.fastmcp_context.request_id,
"duration_ms": (datetime.now(timezone.utc) - start).total_seconds() * 1000,
"timestamp": start,
"status": "error" if error else "ok",
"error": error,
})
return result
El bloque finally garantiza que el log se escribe siempre, incluso si el tool falla. Esto es fundamental para observabilidad real.
Nota importante sobre el acceso al contexto: no es context.params ni context.tool_name — es context.message.params.name. Lo descubrí con un AttributeError en producción.
Docker Compose para el stack de logging
# docker-compose.yml
services:
mongo:
image: mongo:7
ports:
- "27017:27017"
volumes:
- mongo_data:/data/db
environment:
MONGO_INITDB_DATABASE: ${MONGO_DATABASE:-mcp_logs}mongo-express:
image: mongo-express
ports:
- "8081:8081"
environment:
ME_CONFIG_MONGODB_URL: ${MONGO_URI:-mongodb://mongo:27017/}
depends_on:
- mongovolumes:
mongo_data:
Con docker compose up -d tenés MongoDB y su interfaz web en http://localhost:8081. Las variables de entorno están sincronizadas con el .env de la app — una sola fuente de verdad.
Tests: unitarios vs integración
El proyecto tiene dos niveles de testing claramente separados.
Tests unitarios — no necesitan servidor ni DB real:
pytest tests/unit/ -vCubren la entidad Usuario (validación Pydantic), el repositorio SQLite (con DB temporal en memoria), y el caso de uso con mocks del repositorio.
Tests de integración — necesitan el servidor corriendo:
# Terminal 1
fastmcp run main.py:mcp --transport http --port 8000# Terminal 2
pytest tests/integration/ -v
Si el servidor no está up, los tests de integración se skipean automáticamente — no fallan. Esto hace que el CI básico pueda correr solo los unitarios sin infraestructura.
Un test particular que me resultó útil es el de rate-limiting:
pytest -v -m slow # hace 30 llamadas y verifica que el limiter corte en la 26Integración con Antigravity IDE
Para conectar el servidor a Antigravity, el archivo de config es ~/.gemini/antigravity/mcp_config.json:
{
"mcpServers": {
"sqlite-server": {
"command": "/ruta/a/.venv/bin/python",
"args": ["/ruta/a/mcp-sqlite-server/main.py"],
"env": {
"PYTHONPATH": "/ruta/a/mcp-sqlite-server",
"DB_PATH": "/ruta/a/mcp-sqlite-server/users.db",
"MONGO_URI": "mongodb://localhost:27017/",
"MONGO_DATABASE": "mcp_logs"
}
}
}
}Una cosa a tener en cuenta: Antigravity no soporta ${workspaceFolder} en el config. Usá paths absolutos o vas a tener un error silencioso donde el servidor no levanta.
Una vez configurado y con el IDE reiniciado, podés invocar los tools directamente desde el chat:
- “Obtené todos los usuarios de Argentina” → invoca
queries_obtener_usuarios - “Procesá la transacción TX-001 por 150.50” → invoca
transactions_process_transaction
Lo que aprendí
1. FastMCP standalone vs SDK oficial Son dos paquetes distintos con APIs distintas. Si necesitás mount, usá fastmcp (el standalone).
2. Los docstrings son parte del producto El modelo lee los docstrings de tus tools para decidir cuándo invocarlos. Un docstring vago produce comportamiento impredecible. Tratalos como documentación de API.
3. El orden de los middlewares importa Los middlewares se ejecutan en orden LIFO (último en agregarse, primero en ejecutarse). Planificá la cadena en función de qué necesita ver qué.
4. Clean Architecture no es overkill para MCP Puede parecer excesivo para un servidor chico, pero la separación en capas hizo que los tests unitarios fueran triviales y que la lógica de negocio sea completamente independiente del framework MCP.
5. MongoDB es opcional, no crítico El servidor funciona sin MongoDB. Si el middleware de logging falla, lo peor que pasa es que no tenés logs — el flujo principal no se interrumpe. Eso es diseño correcto.
Cómo correrlo
# Clonar
git clone https://github.com/gmaron/mcp-sqlite-server.git
cd mcp-sqlite-server# Entorno virtual
python -m venv .venv
source .venv/bin/activate# Dependencias
pip install -r requirements.txt# Variables de entorno
cp .env.example .env# Levantar MongoDB (opcional)
docker compose up -d# Poblar la DB con datos de ejemplo
python setup_db.py# Correr el servidor
fastmcp run main.py:mcp --transport http --port 8000# Tests
pytest tests/unit/ -v
Próximos pasos
Hay varias extensiones naturales para este proyecto:
- Autenticación: MCP soporta OAuth2 — podría agregar autenticación por token antes de exponer los tools.
- Más entidades: el patrón está establecido, agregar un nuevo dominio (Productos, Transacciones reales) es replicar la estructura existente.
- Streaming de resultados: FastMCP soporta
ctx.report_progress()para resultados parciales — útil para queries pesadas. - Metrics: agregar un middleware que exporte métricas a Prometheus para tener observabilidad completa.
Si construís algo con esto o encontrás algo para mejorar, abrí un issue o mandame un mensaje. El código está en github.com/gmaron/mcp-sqlite-server.
Gastón Marón — Ingeniero en Computación, líder de ingeniería y docente en la UNLP. LinkedIn: linkedin.com/in/gastonmaron